
There are certain things when developing an application that are an absolute necessity from a user perspective but which are not fun to develop … thinking about it, that probably is true for all code that is not directly algorithm-related, which in a end-user application is the vast majority! Anyway, I had sort of the developer equivalent of writers block for the last couple of weeks/months when it came to two things:
- Selection of nodes
- Visualizing non-user data
Node Instancing and Multiple References
When writing a custom scene graph, finding inspiration for it is quite easy: Take a look at OpenSG, openscenegraph, SGI Optimizer, Scenix(previously known as NVSG), etc. The problem is that – if I’m not mistaken – all of them are scene graphs with a primary focus on rendering and none of them handle the user actually modifying the graph or selecting parts of it (to for example delete it, move it, perform some operation on it). But what I’m doing is developing a scene graph for data management that does everything but rendering. In fact, one of the main design goals is to be able to have multiple types of renderer without having to change the scene graph itself.
As far as I know, there are two basic approaches to store a selection in a scene graph:
- Hold a pointer to the node in memory
- Encode the path to the node from the root node (i.e. a list of indices: From the root, take the second child, then the first, then the second, then the third, …)
I never particularly liked working with the latter approach although it can even handle such things as having to restore a selection on previously deleted objects which have been resurrected by the undo system. The downside however is that you constantly have to traverse the tree and follow the path to the actual node instance before you can do anything with it.
The first approach is much more direct but gets problematic if a node is used multiple times in the graph (e.g. all four wheels of a car use the same subtree that contains the rim, the tire, disc brakes, etc). Just storing a pointer to the node would not uniquely identify the path to the root.
The idea is therefore to have some object that uniquely identifies the usage of a node along a path: a node instance. A node instance is an object that holds a pointer to the original node as well as a list of child (in the sense of a child of a group node) node instances. The node instances form a second tree which has the same branching as the scene graph but where the scene graph may use the same node in multiple places, the node instance tree has duplicates. Let’s say Group A is used in 3 places, as a result there are 3 node instances that are associated with Group A, one for each usage. The advantage is that a reference to a node instance is the equivalent of a path but you don’t have to traverse the tree every time you want to use the path! You’re already there, just use the reference from the node instance to the original node.
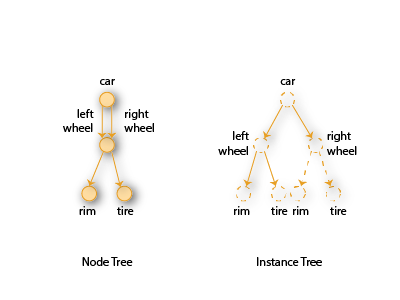
There is a similar approach that uses a tree of unique nodes in the first places and the nodes just share their content. For example, a mesh that is used multiple times in a scene graph would be represented by two separate nodes that both use the same mesh content. However, I decided against that approach for two reasons:
First, as long as a user does not intend to use multiple referenced sub-parts, using nodes directly (and having the system create the node instance tree in the background) is much more intuitive. Second, it seems weird to first create a unique instance in the scene graph and then set the content to the content of another instance in order to add a group to another group. It feels like being forced to always have the indirection between nodes and node instances in mind even when you don’t really care. But I guess, in the end the difference is marginal…
One you have node instances, handling selections is easy: A selection is just a list of node instances that is kept in the scene.
Scene Augmentation
The second problem is how to visualize the selection in the render output. The usual way is to either draw a bounding box or a wireframe overlay in a bright color as seen in the screenshot above. What kept me busy is not what to draw but how to draw it. I didn’t want the renderer to know “there is a selection” and have it draw it in a hard-coded post-rendering step. The main reason this isn’t a good design is that a) the modeling framework is currently renderer-agnostic and letting the renderer decide how/when to draw the selection highlight would mean I would have to re-implement the code when adding a new renderer (e.g. having both a DirectX and an OpenGL renderer); b) there is lots of other stuff that has been drawn that is not actually part of the scene graph: performance statistics, tool visualization, transformation gizmos, coordinate axis, camera/light shapes, the list goes on and on. Having the renderer know about all of these would be a pain in the ass.
So what I came up with is the idea of having scene augmentations. Each view can have a list of augmentation that are drawn after the normal render pass is done. Each augmentation provides a small scene graph segment of its own (e.g. it has a root node, some materials, geometry, etc) and gets updated whenever the view’s scene content is updated by the system. Usually, the augmentation will be rendered as an overlay (which will for example clear the Z-Buffer in case of the OpenGL renderer implementation). During the update phase, the augmentation is passed the scene as a parameter so it can register to listen for changes to the selection, camera movement and so on.
By having an augmentation use only elements of the normal scene graph (instead of custom drawing code), it is renderer-agnostic and will be the same for all renderers. It also gives me a great place to handle custom picking code (in case of the transformation gizmo) and allow me to just use the augmentations the application needs (e.g. on an iPad viewer application, there will be no selection so I just won’t add the selection highlight augmentation to the view). The renderer also doesn’t have to contain code that stores whether or not the selection should be visible or not as user may want to temporarily hide it. That is now just a property on the augmentation.
Next Steps
I only have implemented the first augmentation yet but I’m planning to do the transformation (i.e. translate, rotate, scale) gizmos next. All in all, big steps have been made in making the test application feel like a proper modeling application. There is now a Blender3D-style mouse navigation, a fly-to-selection feature, in renderer picking/selection of objects, transformation panel UI, and more. Granted, I would have loved to spend that time on working on the NURBS tessellator code. But what good is a tessellator if you cannot do a selection or navigate properly in the scene?
Leave a Reply