I remember reading a CVS book back in 2002 or so. It had a quote saying “coding without a versioning system is like parachuting without a parachute”. I always liked this quote as it captured what an essential role version control plays in programming. The world has changed a lot since then. Now almost everyone uses a GIT or SVN as the integration into IDEs has gotten standard and sites like GitHub make it easier than ever. The problem with it is the fact that simply having a version control system (VCS) is only part of the solution: one also has to have the right mindset and policies in place to use it effectively because otherwise, one may very well have a parachute but keep fighting with it as one gets tangled in the ropes.
This is a guide that presents best practices on working with a version control system. It is primarily motivated by all the companies I have visited or worked at where the VCS had gone awry at some point and of course those where it worked like a charm. I assume that the reader is familiar with the basic concepts of a commit or branch and has actively worked with a VCS such as SVN or GIT.
Feedback on this post is very much encouraged and highly appreciated. I constantly try to integrate it and thus improve this document. For a list of update, see the bottom of this post.
Goals
It might be good to define some common goals before going into details. This allows us to evaluate the options that the VCS provides us and choose what fits best. I’ve tried to put them in order of importance but – depending on factors such as the length of the QA cycle before a release or agility of the development process – the optimal order for a particular project may vary.
- It must be possible to pull the exact code that produced a specific release or nightly build. This is an obvious one because otherwise it will be hard to debug/diagnose problems that customers or the QA report.
- It must be possible to create bug fix releases for a specific release and also keep that information in the VCS. Again, this is fairly obvious.
- Multiple developers/teams should be able to work independently with a minimum level of friction when combining their work. If there is only one developer on a project, the exact branching strategy typically becomes less relevant as usually only one feature is worked on at any point in time. The most severe VCS problems arise when there is a large team (>10 developers) that work on multiple features that have varying release schedules.
- It should be possible to create a new release within a short amount of time. There’s nothing worse than approaching a deadline and having to delay it for 3-6 months because there are too many loose ends in the code. As a corollary, the project as a whole should always (=with every commit) improve the software and reduce the things that have to be done, not add to them.
- It should be easy to see what changed between two releases or nightly builds. This makes life much easier for everyone involve: For developers, they can take into considerations what others have changed. For QA, they can limit tests to the areas that have actually changed. Even for product management, having a feel for what areas of the software change and to what amount helps.
- It should be easy to drop a new feature completely without bloating the code base or commit history. Requirements change and one can get to the point where it no longer makes sense for example to integrate a particular framework because a fatal flaw was found. Or in the process of implementing a feature, early user tests show that the feature makes no sense.
- The policies for how a VCS is used should be easy to understand and follow. They should help and protect a developer from causing problems rather than facilitating all the gimmicks a VCS has. Keep in mind that not everyone has in-depth knowledge or even interest ist VCSes. The average developer knows how to check code out and commit but not necessarily what to do when there are merge conflicts.
There are of course lots of other criteria but those should suffice for the discussion at hand.
Collaboration or Backup Tool?
Most developers use a VCS for three things: revert local modifications, get updates other developers have done or commit changes they have done. They try to stay away from branching/merges out of fear that the auto-merge will fail. If it fails, they don’t know or care why and simply try to fix the build errors and make tests pass. They also rarely check out an old version or read through the commit history. So it is fair to say that for most developers, the difference between a VCS and a daily backup system or a file sharing service such as DropBox is marginally.
However, the primary reason to use a VCS is the ability to collaborate with other developers or even whole teams of developers on the same code base. This is usually where things break down: Everything is great if there are only 3-4 developers or if the number of developers is high but the number of commits per day is low. Anything above this and the chance is high that while you have been working on your task, someone else has changed something without your knowledge that affects your work and you should know about. Best case, you see the change and can integrate it in your work quickly. Worst case, things go unnoticed and you ship a critical bug to your customer because you weren’t aware of the consequences of the other change.
Teams have found various approaches how to deal with this – with various success:
- Decouple teams by splitting the repository, e.g. have a front-end and backend-end repository. This usually creates problems because both parts interact heavily. Development and release of both repositories has to be synchronised, it makes it more difficult to work with a full-stack approach, etc.
- Heavily rely on automated testing: While in principle a good idea, solely relying on automated tests does not solve the problem of collaboration, it simply makes it visible. One symptom of this approach is that as the team scales, the build pipeline will fail more frequently and developers are blocked by bugs that someone has committed to the main branch.
- Increase number of meetings: This also doesn’t scale with the number of people on the team. In addition, if someone tells you what he has done instead of you looking what has been changed, there is a heavy selection bias. The author will state what is important from his perspective and not be aware of aspects that can be vital from the listeners perspective.
- …
Note that all these approaches work around the VCS instead of using some mechanism that is part of it. There even seems to be a general inclination to blame the VCS as the root of the problem. Statements like “if we had GIT instead of X, we wouldn’t have this problem” or “we don’t use branches because they don’t work” are surprisingly common… especially among teams who suffer from regression problems and failed build pipelines.
So instead, let’s have a look at the mechanisms the VCS provides us and how they can help solving the collaboration problem.
Learning from History
One of the major benefits of a VCS is that it can be used to see when, how and (potentially) why code has changed. For example, if a bug is found, one is not limited to just debug and fix the problem. The VCS can be used to figure out:
- when the problem was introduced (and thus assessing the damage to customer data)
- who introduced the problem (and use it as an opportunity to learn)
- and – if it has been properly documented – even why the change has been done (and put a possible solution into context)
The last point is one that many developers overlook: I once was fixing a bug and while checking the history of that code, I found that the particular line had been changed multiple times between two variants: One variant fixed bug A but caused bug B. A couple of weeks/months later the QA would find B, open a ticket and another developer changed the line back to its old form because that handled B okay – but of course caused A again with the developer noticing it. A couple of weeks/month later, the QA would find the bug B again and well…
Having a clean, well structured and documented commit history is like a book on how the project has changed over time. The better it is groomed by writing expressive commit messages and choosing the right granularity of commits (too many would flood the history, too few make it problematic to isolate problems or fixes), the easier it will be if someone has to go back in time for whatever reason.
Tip: Never fix a bug without being able to say when (= in which commit) and why it was introduced. If you are not able to do this, it is often an indicator that you haven’t fully understood the problem. Talk to the developer that introduced the bug to verify your assumptions and make sure you haven’t overlooked potential benefits of the original change. If the change was associated with a ticket, try to reproduce the original use case/bug.
Tip: Most VCSes allow the editing of commit messages after the commit. With SVN for example, it can be configured that only the original author is allowed to edit a commit message. So even if someone just wrote a generic message like “implemented x” or forgot to add the reference to a ticket number, it should be pointed out and fixed. This can save a lot of time and trouble if two years later someone has to look something up.
Reading the News
A well kept log also makes it easier to stay aware of what has changed. While almost every developer is used to checking his mails/slack in the morning, it is surprising how few developers read the commit log in the morning. Despite daily stand-ups or project-sync-meetings, the commit log is the one unbiased and unfiltered source of information a developer has. If you are driving on the motorway, you’re also occasionally checking left and right what the others are doing, right?
While it may seem daunting to read every commit and every diff, it doesn’t have to be:
- The smaller commits are and the better the commit message is written, the easier it is to read them.
- Keep commits small but also keep the number of commits low. It’s easier to read through five commits that each implement a small feature or fix a bug than having the same change split over 50 commits.
- Use a good merge/diff viewer: make it easy to quickly browse which lines have changed.
- Skip over irrelevant parts. It’s like reading the newspaper: it’s good to have all articles because you can quickly skip over the ones that aren’t relevant (e.g. the sports section). For source code, one can often skip over whole directories of files containing unrelated changes.
- It’s surprising how well this scales with the team size: the more members a team has, the higher the chance that an individual commit is irrelevant for your task.
- Using feature branches helps abstracting things: instead of having to read 50 individual commits, there is a single larger commit (the back merge) which combines all relevant parts. If the feature is irrelevant for your task, simply skip that one commit. If the feature is relevant for your task, you have the final and tested set of changes in one place and don’t have to read through bugfixes and changes that happened during feature development.
To sum up, the value and effort of reading the commit log heavily depends on the quality of commits. More on what makes a good commit and commit message will be discussed later.
Tip: Having developers reading the log/diffs tremendously helps improve code and documentation quality: if another developer cannot understand what is happening in a commit, it’s a good indicator that either the code is too complicated, the task wasn’t broken down far enough or some documentation is missing. The effects are similar to the benefits of pair programming or code reviews. At least keeping a rough overview of what others have changed in the repository is probably the most under-utilised function of a VCS!
Analysing by History Bisection
Using the latest code and running the application through a debugger without any prior knowledge is often not the optimal strategy for figuring out a problem. It might take time to track down the specifics of why a certain behaviour happens and bugs might be in places where they are least expected.
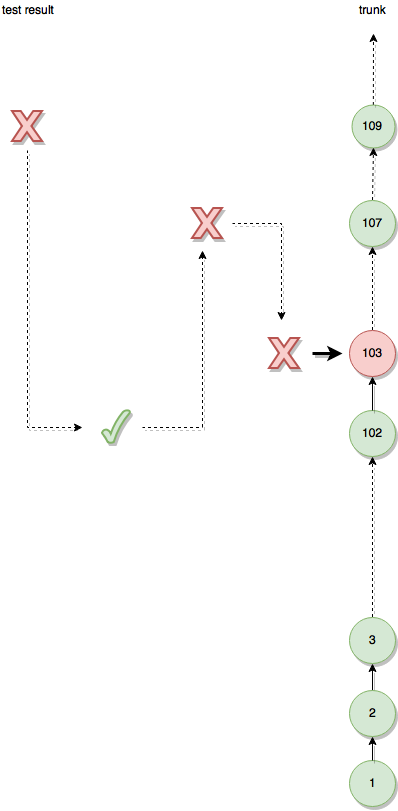
If one has a well kept commit history, it is often easier to initially figure out in which commit the problem first came up. This can be done by checking out some earlier revision where one can verify that the problem did not occur and then narrow down the interval between good and bad revisions by checking out and testing a revision in the middle. This usually takes only a couple of tries and can be done even by junior developers because all one has to do is build a specific version and try to reproduce the bug. Once a revision has been isolated, one a) knows the person who caused it (and who might have the best knowledge on how to fix it) and b) knows which lines of code caused the problem. Here it of course helps if commits were small and didn’t try to achieve five different things in one commit.
Tip: This workflow is so useful, GIT has integrated it into its command set and will automatically check out the next version on your input on whether a particular commit works or not.
Commits
The size of a commit is obviously a crucial factor with many implications for the development and branching model that one uses. Note however that in this context size doesn’t refer to the number of lines of code but rather its complexity. A simple renaming that happens in hundreds of files is easier to understand than for example changing the termination criteria in a recursive function. The optimal size of a commit can rather be found by considering the some basic quality criteria. Most of them can directly be derived from the requirement that a VCS is a tool for collaboration of many developers and the work of one should not negatively impact the work of others.
A commit should …
- … be a self-contained unit of work: After the commit, the project should build and tests should succeed (at least as much as they did before the commit).
- … improve the status quo: A commit should not cause any bugs or technical debt that has to be dealt with at a later point.
- … be final: don’t commit experiments or “hope” that the build system will succeed in building and testing your changes.
- … resolve a task in the project tracking system: we will take a closer look to why this is later.
- … have a single purpose: Either it should refactor something, add a feature or fix a bug, not all in one. There is some leeway here, for example if a refactoring is trivial and only made sense in the context of a bugfix or new feature.
A commit should not …
- … break the build: one should never rely on the central build server to find problems because at this point, a faulty commit is permanently part of the commit history, other developers are blocked from committing, and the problem can potentially spread to other branches.
- … add unused methods/classes: some people like to implement new data objects, commit them, implement the factory that creates them, commit it, add the functionality that uses the factory, commit it, write the unit test and commit it. This unnecessarily increases the number of commits and makes the history harder to read as it is not obvious which commits belong to the new functionality. Also since the functionality can only be tested once all parts are complete, potential bugs are discovered after the initial commits have already made part of the repository which leads to extra changes (for the bugfixes) which could have been avoided.
- … contain commented out code: there really is no reason to do this. Either such a change is temporary (and shouldn’t have been committed in the first place) or the code is no longer needed and it can be removed (since it can always be recovered by going back to a previous commit).
- … be a means to transport incomplete changes to another developer: Either restructure them such that they are an improvement to the software even without the other person’s changes or use a patch/diff to transfer the changes manually.
- … be a way to save a days work: Don’t commit half-finished things just to have a revision to revert or diff to. It will just make things difficult if in the future someone wants to check out an old revision and a number of them make no sense or are broken. This refers mainly to partial commits while in the middle of developing something. The pros and cons of WIP-branches (=work in progress) will be discussed separately later on.
Of course there are exceptions. But if these criteria cannot be fulfilled, it is in general a sign that one hasn’t probably planned a task before implementing it. If a task cannot be resolved with a single commit, break it down into subtasks or create a feature branch. For everything in between, create a patch and store it on your local machine if you really need a backup.
Note: Modern VCSes like GIT partially alleviate those rules. Their ability to squash commits can be used to after-the-fact clean up a history. Also, local-only branches can be used as temporary storage for changes. However, in practice, most developers won’t be savvy or interested enough in rewriting history to keep it clean and local-only branches can cause problems of not pushing the correct changes to the main repository. The problem with keeping a clean repository is that the person who pollutes it (by doing a suboptimal commit) and the person who needs it (while trying to figure out a bug) are usually two different people. So the natural incentive to worry about the commit history is low. On the other hand, sticking to the rules above helps the average developer to find the right balance of what should and should not be a commit. In general, keeping things simple when it comes to VCSes seems to help.
The 1:1 Relation of Commits and Tickets
It has been mentioned before that commits and tickets/tasks in your tracking system should usually have a 1:1 relationship. Why is that? The basic underlying assumption is that development happens for a purpose: a project goal needs to be completed, a product sold to a customer, a bug fixed for an existing customer. Tickets are used to manage the project, to define what needs to be done and in what order. If we end up with code changes that do not relate to any ticket, either of two cases can have happened:
- the work was required to reach the project goal: for example, a bug was found and fixed and the product couldn’t have shipped without the fix. In this case, it makes sense to create a ticket so the work is correctly tracked within the project. The ticket not only informs other developers, QA and the product owner that something relevant has changed, it also tells them how you spend your time and why you may not have fulfilled as many stories/tasks as was expected.
- the work was not required to reach the project goal: for example, a bug was found and fixed or a refactoring done but it wouldn’t have needed fixing/refactoring to be able to ship the release. In this case, the modification shouldn’t have been done in the first place and most likely not be committed. Even if the modification has some benefit (e.g. improve readability of the code), it comes at the cost of having spent valuable project time (which cannot be used for things which are in the scope of the project) and has the inherent risk of introducing new bugs or increasing the amount of testing needed for QA.
Tickets are also a great place to state why some code has been changed, attach steps to reproduce a problem or put other information that does not belong in the code directly – especially for non-developers that may not be able to read/access the commit history.
Tip: It’s quite common that one starts with the intention of doing a single task but ends up with local modifications that also contain some bugfix or refactoring. Even if one has already completed the necessary coding, it often makes sense to break the work down into individual tasks/bugs and commit them separately. Simply create a copy of the file or patch of the modifications, revert the changes and then only apply the changes needed for one of the tasks/bugs. After committing those changes, copy over the original modified files and see if the remaining changes are now small enough for a single commit or need to be split into yet another commit. For GIT, a similar workflow can be achieved using the built in stashing-functionality.
Writing a Good Commit Message
One of the most important aspects of documentation is “why was something changed”. Code by itself can only tell one what it does (and even that gets hard if the code is of poor quality), not why. Unfortunately, a VCS has no mechanism to force a developer to record that crucial piece of information, same as a compiler doesn’t force one to put good comments into the code. This often leads to the question: what information should be contained in a commit message? Here are some best practices:
- Reference the ID of the task/ticket in the tracking system (Gira, TFS, TRAC, …) that caused the code change. Systems like TRAC can be configured to copy the commit message into the ticket which is helpful when looking through a project from the planning/management perspective. Think of the ticket as the story of what needs to be done and the commit message as the conclusion what has been done.
- If someone did a code review, mention the name of the person. This is for both proofing that the review has been done as well as finding a substitute if the original developer is not available to answer questions for that code.
- List what “areas” of the application are affected. Is this just a single importer or are all UI elements affected? If the change was within a specific class or sub-system, mentioning it will make it possible to use the VCS’s text search on the commit history.
- Express why the change was done and how it changes the behaviour of the software.
- Write the message such that someone can read through the history and can quickly decide whether or not the commit is relevant for him/her. If you try to find a bug, having a commit message saying “just documentation, no code changes” actually helps to skip that commit.
- Be careful with categorising commits (e.g. chore, task, feat, …). There isn’t really a difference to the effects of a code change whether it comes from a feature or task but it can be misleading (e.g. “this is just a chore so the risk of being a bug in here is smaller”). Instead express why something has been done (e.g, “this fixes bug 1234 by…” or “added documentation for …”).
- It should be written in a way that it can be understood by non-developers. A number of build systems such as Jenkins will list the commit messages in the build which then can help QA or product management to understand what happened.
- It should not contain information that belongs elsewhere. For example, low-level technical stuff rather belongs inside the code itself.
Tip: TortoiseSVN for example allows adding a custom text box in the commit dialog where the developer can be forced to add the ID.
Branches
From a bird’s-eye view, a VCS consists of a number of commits (=units of work) along a number of branches (=sequences of commits). Regardless of which system is used, there is always one initial main branch whether it is called trunk in SVN or master in GIT. Other branches can be spun of as copies of any previous commit in the VCS and help to isolate work. For the VCS, all branches are pretty much equal. It can for example make sense to never create a second branch and just commit everything on the main branch. On the other end of the spectrum, one can create branches of branches and never commit on the main branch. The point is that the system does not really care, it is the user that needs to find a suitable way of using the available capabilities: a branching strategy.
Feature Branch
The typical use case for a branch is the development of a new major feature. Working on a separate branch isolates the changes done for the feature and keeps the main branch clean until the feature is complete. At this time, the feature branch is updated with the changes that in the meantime happened on the main branch. This feature branch becomes the latest version of the main branch plus the feature. This version is then merged back so that the main branch becomes that exact version and the feature branch is closed. This is the basic theory that everyone knows but there are a lot of subtle and not so subtle implications worth considering.

How to Avoid Merging Hell
Imagine a worst case scenario: At the beginning of a release cycle, multiple teams have branched off their own branches. After 9 months, feature freeze is near and all the teams rush to get their work back to the main branch. Each team updates their branch with 9 months of changes from the main branch and gets a ton of conflicts. After fixing them, the first team merges back to the main branch, most likely without proper testing. After all, much has changed in 9 month and before the update no one has ever checked if there have been conceptual changes on the main branch that break assumptions on the feature branch. Also the team doesn’t want to block the main branch for a longer time because bugfixes have to be made on the main branch and other teams are waiting to re-integrate their features.
Eventually, the team gets the code to build again, runs the smoke test and calls it a day. They merge back and are done. The other teams however have a problem: They now not only have to deal with 9 months of changes from the main branch but also 9 months worth of changes from the feature branch. So their merge conflicts will be even worse. And so on for the next team, and for the next team, and …

While it may seem a but contrived, this is exactly what happens in a lot of projects. All hell breaks loose and everyone vows never to use feature branches again. The QA is pissed due to the sudden rise in bug count and demands that branches are never used again. Policies are created such that everyone only commits on the main branch. However, that only creates other problems:
- If a feature consists of multiple commits, it becomes hard to evaluate the changes done by the feature because they are interleaved with other changes happening. With a feature branch, there is by definition a single point (the back merge) where one can see all the feature-related changes in a single commit. It can be reviewed and if necessary be blocked if architectural changes need to be made.
- If a feature is developed directly on the main branch and during development mistakes had been made and fixed or architectural choices reverted, they become part of the main branches history. Using a feature branch, the main branch does not contain them. From the main branch’s point of view, there is a single commit that just contains the tested and approved version of the implementation.
- When using feature branches, different commit policies can be used. For example, one can define that all commits on the main branch need to be code reviewed while feature development does not. Or that unit tests need to be performed before commit on the main branch while only limited tests are needed on the feature branch. Without feature branches, all development has to conform to the same set of policies which will most likely be a weak compromise.
- If a feature is part of the main branch but it’s development is not completed in time for a release date, feature toggles have to be used. The problem with feature toggles is that it can become tricky (or often impossible) to guarantee that the toggled-out code does not have any side effects. It just takes someone to have missed checking the toggle within a single method to introduce a crash or change behavior. With feature branches, one can guarantee that the changes cannot effect the main branch because they are on a separate branch. More on this later.
There are many other reasons why it is beneficial to use feature branches. The problem with feature branches is not inherent in their existence, but the way they are (often incorrectly) used.
Merge Policies
Here are some best practices when working with feature branches:
- Update the branch regularly: while working on a branch, code continues to evolve on the main branch. The longer the interval between the last update from main and the point where it is supposed to be back-merged, the more complicated the merge will be. It usually helps to have a rule like update feature branches on every Monday or at the beginning of a 2 week sprint unless the main branch has becomes unstable.
- Whenever you merge, read the diff: when updating a feature branch, check the changes from the main branch for any potential problems when applied to the logic on the feature branch. Just because it compiles doesn’t mean there aren’t problems. When re-integrating back into the main branch, check the diff to make sure that no unwanted changes go back to the main branch. This includes uncommitted code, unused code, etc.
- Feature branches should have a limited lifetime: If a feature evolves over a long period of time, the number of lines modified by the branch easily grows beyond something that can be properly reviewed when merging back to the main branch. Aim for a lifetime with a maximum of 1-2 months. If that doesn’t seem possible, the feature should be split into multiple, self-contained improvements and each step is merged back to the main branch before creating a new feature branch for the next step.
- Orchestrate the order of features: by planning in what order which feature is implemented, the region where they overlap can be minimised.
- Keep the branch as small as possible: The smaller the difference between the feature and the main branch, the easier it will be to merge and the less it will have an impact on other feature branches. If refactorings or bugfixes are needed for a feature to be implemented, do them on the main branch and then merge them over. With every commit one should reflect: what part of this is something that really belongs to the feature and what part of this could have been done on the main branch? If the feature branch would be deleted without back merge, would anything except the feature itself be lost?
- As a corollary, if possible do not perform reformatting or moving code between files on feature branches. When merging back to the main branch, the commit should read like the main branch would have been ideally suited for the new feature when development began and just a minimal amount of changes are caused by the feature.
- Review the changes that come to the feature branch: Since people are working on the main branch without exact knowledge of what happens on the feature branch, it usually is a good idea to go through the changes before completing the merge. Just because the merged code compiles does not mean that it is conceptually still working. For example, a new enum value might have been added and the new switch statement in the feature’s code will not handle it yet. Compiles fine, causes lots of trouble.
- No cherry picking: Do not merge single changes from the main branch to the feature branch. While it is technically supported and in many cases can go okay, it can lead to subtle problems that are hard to find. Also, from a conceptual standpoint, it is much easier to think in terms of taking the main branch as it has been tested and reducing the distance of the feature branch by all those changes.
- Do not merge changes from a feature branch to main except in the final back-merge. Merging back and forth between main and feature branch can cause very weird conflicts, especially in SVN.
- Close/delete feature branches when they have been re-integrated. In SVN this is mandatory but it also makes sense for other system because it helps mentally breaking down larger features into multiple stages.
GIT: Rebasing vs Always Merge, Fast-Forward Merging
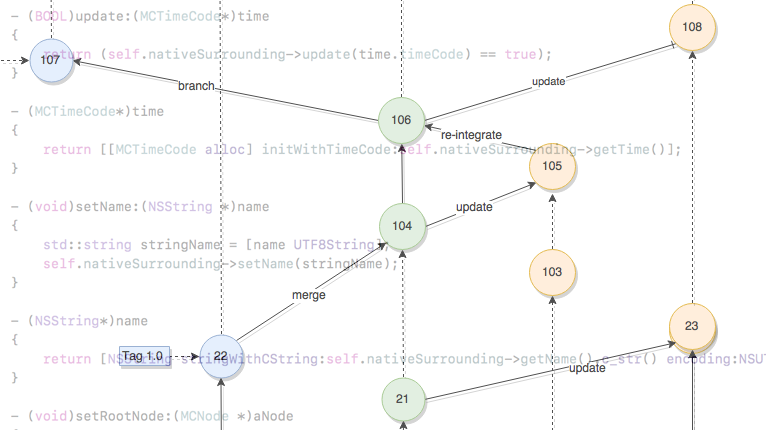
In contrast to SVN, GIT has the capability to actively change the order of commits after the fact. This can be used to fake that development on the branch has happened not in parallel to the master branch but building on top of it. While this simplifies the commit history with respect to branching (it looks like the branch never happened), it often obfuscates and complicates the commit history with respect to code evolution.
Imagine a feature branch. During its development, new things are added, existing code is changed, testing and reviews are done and as a consequence architectures or class designs are adapted and bugs are fixed. In the majority of cases, the final code of the feature branch will not contain all code that was create/modified during its development. With rebasing, those intermediate steps (such as a bad design or a commit that broke functionality) are part of the master branch’s history and all developers that use the history will encounter those commits. When reading through the history, all developers have to read through all the commit messages, whether they are interested in the feature or not. When bisecting history to find a bug, all the (for unrelated reason) broken commits have to be considered. And – perhaps most importantly – it gets impossible to checkout the code version for a particular date.
If on the other hand the feature branch is merged back (and using the git option to avoid fast-forward merges), the master branch contains a single commit where the final tested and working version of the feature came into the master branch. Not interested in the feature? Simply skip that one commit. Interested in the effects of the feature: look through that one commit (without the intermediate steps). Need to figure out why something was done in the feature, simply look through the history of the branch.
The image below illustrates this: with merging, a developer who’s work is unrelated to the feature can safely ignore all orange commits because only the back-merge commit is relevant. It is also immediately obvious which commits belong to the feature and which don’t.

So while it might seem tempting to rebase and have a linear commit history, using feature branches actually groups and abstracts large portions and makes it easier to see that happened on the master branch. And it actually reflects how the code evolved! Of course, if you are not interested in that, the rebased version seems simpler to you. In fact, there seems to be a correlation in real life between teams advocating rebase and teams that don’t not use the ability to analyse the repository’s history during development.
There are other, more complex disadvantages to rebasing. So if you’re still not convinced, see for example:
- Please, stay away from rebase
- Atlassian Blog – Git team workflow: merge or rebase
- Why you should stop using GIT rebase
- Visualize Merge History with git log –graph, –first-parent, and –no-merges
There is however one situation where rebasing should be the default: when working with a central master repository (as most companies do). Imagine you did a single commit (e.g. to fix a bug) and want to pull the latest changes on the branch you are working on. Though technically this is a merge between two branches (the local and the remote one), from a feature stand point it is just a copy of the branch and the fact that the commit has been done remotely should not pollute the history with merge commits.
Tip: It has taken me a while to understand why so many GIT users find a history with merges harder to read than one without and surprisingly it boils down to the tools they use! TortoiseGIT for example by default hides commits that happened on a branch that has been merged in (i.e. hiding the orange commits in the image above) and gives an option to expand to show all commits. With GIT or with gitk on the console, this can be achieved by using –first-parent (of which most developers seem to no be aware of). But neither CLion nor Eclipse (EGit) support this option at all! So when getting into discussions about merge vs rebase, check what tools your counterpart uses!
Branch Reduction and Partial Updating
There are a couple of techniques that can help when branches get big. The first I like to call branch reduction: during development of a feature, one often inadvertently performs changes/fixes/refactorings that could have happened on the main branch. After updating a feature branch to the latest version of the main branch, do a diff between main and the feature branch. If there is anything in there not directly related to the feature, manually copy over the changes (or rather do it with a merge tool like WinMerge) and check them in on the main branch as if they had happened there. Then do another update-merge to the feature branch. Depending on the VCS, this may cause conflicts because lines have been modified that previous had been modified on the feature branch. But since you know those are only changes that already existed on the feature branch, they can be ignored and the code version on the feature branch can be kept. However, as a result, those lines are no longer different between the main and the feature branch and the branch distance has thus been reduced.
The other trick can be applied when a lot happened on the main branch. Instead of merging all new changes to the feature branch in one go, it can help to do it in batches. Take the first few changes, merge them over, solve the merge conflicts, commit, then merge the next few changes, merge them over, solve the merge conflicts and so on.
Feature Toggles vs Feature Branches
I have mentioned feature toggles before. In generell, either a non-user-accessible configuration value or a compile-time switch is used to turn off all code for a feature. There are cases where this is easy to guarantee, such as removing the menu entry for a new dialog such that it cannot be reached anymore or returning null from a factory creation method if the feature is deactivated. However, isolation isn’t always that easy and things can slip through. For example, the dialog may be hidden but there might be the scripting API that still allows reaching the functionality of the feature.
As a result, feature toggles should primarily be used as a product owner decision (e.g. the feature is ready but pushed to a later release for marketing or legal reasons), not as a poor substitute of a feature branch. The equation slightly changes if your application has really great automated testing because the risk of something slipping through is reduced. However, feature toggles still have the drawback of the feature’s code actually being part of the main branch. If the feature is scrapped or has to be re-designed, the code changes done by the old implementation have to be removed. Only use feature toggles if the implementation of a feature is final and complete.
Work in Progress Branches
WIP-branches are basically feature branches with the intention of being very short-lived and containing so few changes that the term “feature” would be misleading. For example, a developer might be working on a bug fix and at the end of the day he pushes his changes to a WIP-branch such that another developer could pick up the work.
WIP-branches are quite common in GIT repositories, especially for development teams that had bad experiences using feature branches (and don’t actively utilise the repositories history). Some teams even have the rule that all code has to be checked in at the end of the day. While the intention of saving all work in the repository might seem enticing, there are drawbacks:
- WIP-branches are often forgotten and never deleted, obscuring which branches are in active development and which are not.
- Unless using rebasing and fast forward merges, they create unnecessary back-merge commits and thus pollute the commit history. See the discussion on rebasing further down.
- They often lead to the creation of partial/incomplete commits which – as stated earlier – makes it harder when having to go back the history and checking out older revisions.
It is difficult to make a hard case for or against WIP-branches. In the end, they should be treated exactly the same as feature branches: keep the number of them low, avoid partial/non-working commits, constantly update them with the changes done on the main branch and delete them as soon as they have been merged back to the main branch.
Tip: Avoid policies that force developers to commit partial or even broken code to the repository. In most cases, it’s not really relevant if code is committed one day or the next. If partial code shall be handed over to another developer, using patch files (either attached to the ticket or send to the other developer) fulfil the same purpose without polluting the commit history. If you expect a WIP branch to continue over multiple days, treat it as what it is: a feature branch.
Release Branches and Tags
The other common type of branches is called a release branch. They are branched out from the main branch to fixate a code version and make the main branch ready for new development that should not be part of a particular release. There are three common approaches for when to create a release branch:
- At code freeze: If a software has long QA cycles, a release branch is created when all the main features have been implemented and/or changes need to be made on the main branch that should not be part of the release. While QA is testing, bugfixes are made on the release branch and the development branch continues with the work for the next release. When all relevant bugs are fixed, a tag is set on the release branch to mark the version that is shipped.
- At release time: If there is no parallel development and/or automatic test coverage is so good that the QA cycle is only very small, the actual release version is created on the main branch. When a release is ready, the final commit is branched out in anticipation that a bugfix release will follow anyway.
- On demand: Similar to 2., the release is done on the main branch. Instead of a branch, only a tag is set to mark which revision was used for a release. If a bugfix release becomes necessary, the tagged version is checked out and it is branched off from that commit.
The difference between these approaches is minimal. The fixes done on a release branch are merged back to the main branch so that they are carried over to the next version. If a bugfix release is needed, one either creates the release branch (for 3.) or continues the existing release branch. In case multiple bugfix releases are required for the same version (e.g. customer A needs only fix 1 but not fix 2 and customer B needs only fix 2 but not 1), sub-branches of the release branch are created. Usually it helps to have a dedicated release branch even if only because it makes setup of a release build in the build system easier.

It is pretty straight forward to manage release branches as long as one remembers to always merge toward the main branch. The only important factor is to not skip branches. For example, if a fix is done on a sub-release branch, that fix should be merged to the release-branch, then from there to main, then from there to the feature branches.
Summary of Branch Policies
Here is a list of the most important aspects mentioned above plus some bonus ones:
- Keep the main branch stable at all times.
- Do code reviews before committing to main.
- Don’t branch off from feature branches.
- Don’t cherry-pick commits.
- Don’t cross the merge direction: feature branches only update from main until they re-integrate. Release branches only merge their changes into main and never update from it!
- Don’t skip intermediate branches while merging.
- Merge updates from the main branch to the features branch on a regular basis. E.g. every Monday unless the main branch is not stable.
- Keep the development lifetime of a branch below 1-2 months. It usually is fine if the back-merge is delayed by a few month as long as only updates from main and no new development is done on the branch.
- Use feature toggles as a product decision, not for code isolation.
- Use the standard branch/tag structure. Do not invent a fancy directory structure (e.g. renaming trunk to main) because most tools will assume that the main branch in SVN is trunk and for GIT is master.
- Don’t use svn:external or some other linking mechanisms between repositories.
- Don’t use VCS as local modify history, rather structure your work into tasks that are self-contained.
- For GIT: (probably) don’t use gitflow. While it has a lot of similar concepts (reading up on Vincent Driessens excellent write up of his branching model was one of the factors leading me to finally write this post after years of thinking about doing so) to the best practices presented here and there is a benefit of having standardised commands, doing the main development not on the master branch is very counter-intuitive and there seems to be no real benefit to it. So basically a standard repository structure is traded for ensuring that developers use the right GIT commands. This may or may not be a good trade-off depending on the experience of the developers doing the merges.
Repository Size and Scope
Finally, a word of warning: while one can check in arbitrary content and GIT handles binary files very well, one should not fall for the fallacy of “putting everything in the repository”. For one, the disk space for each check out gets unnecessary large (and I tend to have multiple branches checked out in parallel as I often have to jump from project to project) and the repository can get unresponsive.
- 3rd party libraries: It is usually a good idea to put the source code of large 3rd party projects into a separate repository and only check-in the compiled binaries into the main repository. For one, it reduces compile times of the project (because the 3rd party libraries won’t be part of the build chain). For the other, it reduces the number of files that have to be checked out and the number of commits that happen (because the modifications happen in another repository).
- Deployment content: Things like a 2GB MS SQL installer might be necessary to create the final deployment target (e.g. an ISO image) but keeping such large files in the main repository is usually a bad idea. Have it in a separate repository and have the build system copy over the files.
- SVN-externals: don’t use weird cross referencing between repositories in an attempt to be nifty. Usually what happens is that someone tries to modify something in repository A and does not realise that it also has effects for repository B.
- SVN-externals (part 2); don’t use inner-repository links to bundle subsets of the repository. For example, one repository I saw had sub-folders that bundle the 5-6 main folders one needed to build a certain product without checking out everything. In most cases, using such relative links is a sign that there is too much unrelated content in the same repository. If there is a shared component, move it to a separate repository and treat it like a 3rd party component with its own release cycle.
- Media files: Be careful about checking-in raw media files like the Photoshop PSD files for your app icon. The way the format works, even changing a tiny bit causes a new 50-100MB PSD and your repository gets huge quickly. It usually makes sense to have these in a separate repository and either tag the release versions or copy over the final version for a new release to the main repository.
- End user documentation: similar to media files, it can be risky to put the raw source files into the main repository when just the final PDF export or HTML is needed to build.
Of course using multiple repositories comes at a cost. One has to be careful to tag release versions in all repositories. In the end, a balance has to be found: what parts really need to be versioned with the source code and which parts can be put somewhere else to not bloat the repository. Use the criteria at the beginning of this post as a guide: it should be easy/quick to checkout and build a specific version/branch because that happens a lot. For some assets that means they should be part of the main repository, for others it means they should not.
Summary
I hope this information helps clarifying some of the finer details of using a version control system. As with every other tool, the system itself can only provide mechanisms. It is up to the users to use them in a way that fits the project. With the right amount of planning and some discipline, using multiple feature branches at the same time works just fine and actually improves how software development is done. Same with commits: with the right granularity and proper commit messages, the commit history becomes a very powerful tool. Use your VCS, don’t abuse it!
Update Mar 10, 2018: Changed order of sections for improved readability. Added section on VCS as collaboration vs backup tool. Added section on using the commit log to catch up with recent development. Added sections on WIP-branches. Add section on GIT rebase vs merge. Moved and extended section on 1:1 relation between commits and tickets.
Update Apr 8, 2018: Extended section on GIT merge vs rebase with the thesis that the choice for rebase is often caused by insufficient tool support.
Leave a Reply